Why is it relevant?
Administrations in many countries have already embraced open data. For them, open data helps to facilitate transparency, accountability and public participation. For scientists, open data enables studies aiming to understand global problems such as climate change and helps to solve problems such as disease, crime or famine. Computer engineers can also benefit from open data sources as inputs for machine learning training. Many Citizen Observatories are even obliged by their funders to share their data as part of the data management policies.
How can this be done?
In sharing data, there is no single solution that suits everyone. Some users will simply need to see the data, while others will need to analyse and combine it. The open data movement suggests different steps that you can gradually pursue.
Once the data licence has been selected for the Citizen Observatory, the next step in making it public is to present the data as files in a project website or in open repositories (such as Zenodo). But there are many formats and many data models that can be used. It is important to accompany the data with metadata that describes the data that were collected as well as the data model (what the observed values mean). By distributing the data in a format that is based on an open standard and easy to use, we prevent misinterpretation of the data and facilitate their usage. These files can be accompanied by code to analyse the data (as done by GROW, using Github to share and provide their analysis code on soil moisture for crop growing in Portugal using Python Jupyter Notebooks). In the big data world (where distributing files becomes impractical) it is even better to provide a service that gives access only to the part of the data that users really need. Examples of good and useful services that implement common standards approved by the Open Geospatial Consortium are SOS (Sensor Observation Service) and the SensorThings API. Both fall under the Sensor Web Enablement umbrella, and both allow scientists to retrieve sensor and time-series data filtered geographically, temporally and by data type in JSON or XML format.
Some global platforms where you can share your data:
- The GEOSS portal is an access point for users seeking global Earth Observation data, imagery and analytical software packages;
- The Global Biodiversity Information Facility (GBIF) provides open access to data about all types of life on Earth;
- The Ocean Biodiversity Information System (OBIS) is a global open-access data and information clearing-house on marine biodiversity for science, conservation and sustainable development;
- Many others exist related to specific topics (such as https://scistarter.org/ and https://www.zooniverse.org/). The European Open Science Cloud (EOSC) offers an extensive catalogue of resources on where to find data, publications, tools and other resources in Europe.
Ground Truth 2.0, Scent, GROW and WeObserve set up Citizen Observatories that applied these standards and improved data sharing. To allow for the integration of the observations into new models and applications, Scent implemented the Harmonisation platform that later became discoverable through the GEOSS Portal, where Earth Observation data from all over the world can be searched. A combination of shared solutions can cover the needs of more users. Many citizen science data platforms, such as iNaturalist or Spotteron, offer an export to CSV files for occasional downloads, as well as open APIs to create a permanent connection to the data.
Example from the Landsense project
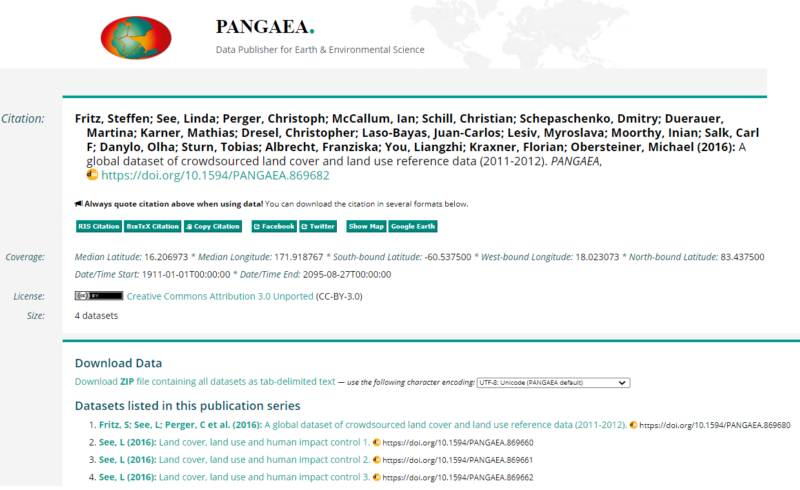
In LandSense, we use the LandSense Engagement Platform to openly share data. We use a distributed system for this. The data from the different citizen science campaigns are hosted with the various project organisations but are accessible on the platform. This also helps to ensure that access to the data can be sustained beyond the lifetime of the project. Landsense data is also uploaded to Zenodo and Pangaea for data access and data preservation purposes. The paper “Global dataset of crowdsources for land cover and land use data” illustrates most of the good practices necessary for data sharing. The license is specified as a Creative Commons 3.0 resource. It uses the CC-BY squema and allows any possible usage, including commercial, the only requirement being the need to acknowledge the data sources. The data is accompanied by some medata representing the spatial-temporal context. To access the data, a series of easy to download ZIP files are provided. These zips contain a text data structure that uses tabular data. This data service does not allow for easy extraction of a subset of the data, but given the amount of data contained in the zips, this should not be necessary.
Useful Resources
WEBSITE: WeObserve marketplace contains several openly accessible data sets produced by LandSense, Ground Truth 2.0, Scent and Grow projects. This website concentrates the work done by thousands of citizens during the duration of the project activities.
VIDEO: Creative Commons: Wanna work together in the Creative Commons website illustrates the need for open licences. In the website, CC licenses are described and can be selected based on the need to provide attribution, allow commercial use, permit derivative works, etc.
REPORT: The “OGC Citizen Science Interoperability Experiment Engineering Report” describes the first phase of the Citizen Science (CS) Interoperability Experiment (IE) organised by the WeObserve Interop CoP and provides examples on data sharing standards applied to Citizen Observatories.
FAIRsharing: FAIRsharing is a community-driven resource with a growing number of users, adopters, collaborators and activities, all working to enable the FAIR Principles and to make Standards, Knowledge Bases, Repositories and Data Policies FAIR.
You may also be interested in:
I want to work with data…
…by integrating data from several Citizen Observatories/other sources
I want to generate insights & results from our data & knowledge…
…by visualising and interpreting the data
I want to achieve impact with the Citizen Observatory results…
This work by parties of the WeObserve consortium is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. ![]()