Why is it relevant?
Deciding what kind of data the members of your Citizen Observatory should collect depends on the issue that your Citizen Observatory wants to address and what data and knowledge is still needed. Moreover, this decision needs to be informed by relevant scientific expertise in order to generate valid and reliable data and results.
How can this be done?
Citizen Observatories are based on citizens observing specific aspects of the environment, sometimes using equipment. For this kind of data, the user’s identification, the time and place of the observation, the value of the observation and some supporting material like images, audio recordings or videos for validation purposes are usually collected.
Observations can be as simple as registering a temperature or as complex as taking a lot of measurements as in the RiuNet project, where citizens conduct a complete scientific analysis of several organic and inorganic parameters indicating river water quality. These types of observational data include biodiversity observations, environmental monitoring, meteorological observations, hydrological measurements, land cover mapping and more.
In some cases there is no data collection by validation or interpretation of scientific data, and no contribution to pattern recognition or image analysis. An example is citizens helping scientists to map the ocean trajectories of marine microbes within a simulated web environment (the Adrift project). Another is the annotation of satellite observations or other pictures with what humans can recognise (such as identifying wildlife captured by motion-triggered camera traps). In particular, Zooniverse is probably the most well-known platform for hosting projects where citizens can participate from their homes, just by using a computer and their time.
Example from the Citizen Observatory of Water in the Alto Adriatico Region
A challenge for water management is the reduction of risk related to extreme events such as floods. Flood management requires the timely provision of early-warning information, particularly in densely populated urban areas. This information depends on reliable water level predictions, created through hydrological and hydraulic models. Yet the performance of these models is often uncertain due to the lack of sufficient observational data. In the Brenta-Bacchiglione catchment area, AAWA has chosen to use the Citizen Observatory on Water to collect complementary sources of hydrological monitoring data to obtain a more spatially distributed coverage, using dedicated apps, easy-to-use physical sensors and other monitoring technologies, linked to a dedicated platform. The crowdsourced water level observations are assimilated into a flood forecasting system: into the hydrological model by means of rating curves assessed for the specific river location, as well as directly into the hydraulic model. This improves the flood forecasting accuracy by integrating physical and social sensors distributed within the river basin, ensuring high model performance (see https://doi.org/10.5194/hess-21-839-2017; https://doi.org/10.5194/hess-22-391-2018). Other environmental variables, such as the vegetative state of the embankments and the river bed, are important for the calibration of the hydraulic models, and for evaluating the hydraulic roughness along the river. On the other hand, knowing the exact location of the flooded areas during a flood event and the relative water height can be useful both post-event to evaluate and improve the reliability of the model, and during the event to plan civil protection operations. The collection of these data in the Brenta-Bacchiglione catchment area is also entrusted to the Citizen Observatory, being easily identifiable through the use of a dedicated app.
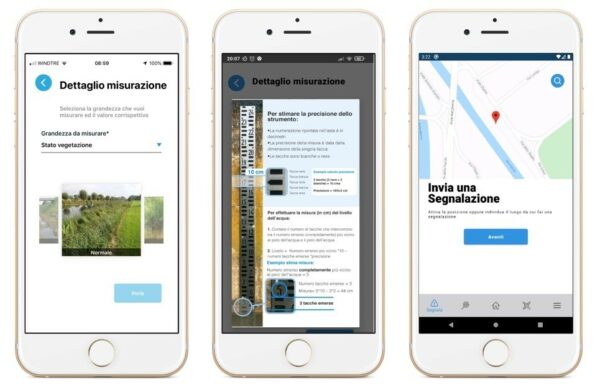
Deciding what data to collect implies that you have identified through a gap analysis what data and knowledge you need and what already exists about the questions you are trying to address (more here on how to find out what exists already).
For each issue (also called ‘monitoring theme’), you need to specify the following aspects:
- What needs to be observed,
- Where does it need to be observed,
- How often does it need to be observed,
- By whom, and
- How.
You can answer these questions by creating the following table that actually defines the data model (i.e., the form of each observation). This will help you ensure alignment of your approach and remain focused. It also allows you to keep an overview if your Citizen Observatory needs to address more than one monitoring theme.
In order to define the type of data your Citizen Observatory needs to generate, you should think about the question you are trying to answer.
The parameter to be observed defines what should be collected and can be a list of names to be captured (with their units of measure, e.g. a temperature in degrees), pictures and annotations describing what is being observed.
Scientists can advise you on where the data needs to be collected (in a limited or in a vast zone, predetermined or random, in the field or from your computer at home) and how often (e.g. whether repeated observations are needed for the same sample).
You should take into account the type of information to collect, the sensors and technologies required, and in what level of detail and precision volunteers should collect that data (i.e., to comply with existing taxonomies), while also keeping in mind the implications in terms of personal data collected, the quality of the data and the provision of adequate metadata. The methods that should be employed for the definition of the above mentioned elements depend on the respective application domain and may differ from project to project.
When defining the data collection scheme it is essential to adhere to standardised definitions provided (OGC, INSPIRE, Public Participation in Scientific Research, etc.) in order to facilitate interoperability and combined use with other data sources.
The data collection scheme can inform the metadata describing the data set resulting from your data collections. Deciding on some metadata elements in advance can help you define the more technical aspects of your data collection scheme, such as the desired resolution of the data collected and thus the coordinate reference system used. See more on metadata for managing your data here and for sharing your data here.
The process of creating a data collection scheme can help a community to discuss what should be measured, when, where, how and by whom. Having a map of the geographic area where you would like to collect data allows everyone to pinpoint the location where they can capture data. Another useful tool is a shared calendar, so that everyone can collaborate on the best dates and times for capturing the data.
When defining suitable instruments and tools for your data collection, you need to consider the following:
- Type of information: Different approaches require different types of data collection. Sometimes textual information is enough, but other times you may be looking for a photograph, sound or video recording, a physical sample or a digital file.
- Technology required: If observations cannot be reported with only the visual observation of the citizen, a sensor will be needed. A careful selection of the sensor based on the kind of instrument, brands, models, precision and stability should be conducted. Sometimes a DIY sensor could be a possibility.
- Contextual information and privacy: The data itself should be accompanied by contextual information, such as the date and time of collection, location, observer and conditions.
Example from the LandSense project
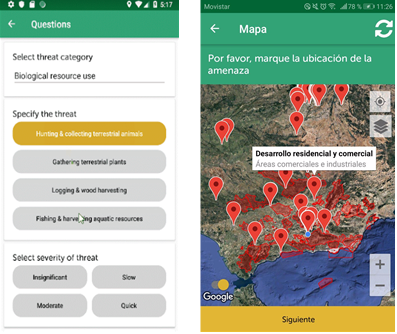
Working with partner BirdLife International and the associated monitoring organisations on the ground in Spain and Indonesia, the overarching aim was to collect data on threats to bird habitats in areas of importance to birds and biodiversity. The categories of threats were provided by the International Union of Conservation of Nature, so the challenge was to develop a tool for collecting this information on the ground. A simple-to-use menu of threats was embedded in a mobile app (called Natura Alert) to which additional comments, photographs and videos can be added. To render the threat information even more useful, additional questions were asked regarding the longevity and spatial extent of the threat so that these could be linked to the annual threat assessments that are undertaken by BirdLife for each area of importance to birds and biodiversity. The threat data were then made available via the Natura Alert web application, including contextual information such as the location and the date and time of collection.
Screenshots from the Natura Alert mobile app, showing the choices for the type of threat on the ground (left side) and a map showing the locations of other threats (right side).
Useful Resources
BOOK: The AfriAlliance Data Collection Handbook is a practical manual focusing on the development sector and the collection of data. It covers the main elements to consider when designing and implementing a data collection project.
BOOK CHAPTER: The chapter “Design and development of geographic citizen science: technological perspectives and considerations”, in the book ‘Geographic Citizen Science Design: No one left behind’ highlights the various impact of information technology on the aims, goals and missions of citizen science and Citizen Observatories.
You may also be interested in:
I want to work with data…
I want to know what data and knowledge we need…
This work by parties of the WeObserve consortium is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. ![]()